In recent times the Kafka has become a buzzword in the industry, it all started with Linkedin trying to manage the large amount of the data across different applications and data store.
Although earlier systems did provide methods of replication(mostly at database level), high throughput and reliability. One of the major challenge was to connect these technologies into a seamless integration to build an enterprise level application. Also how to handle failures, what if there was a bug in the consumer, you processed the message, now the data is corrupt. Can we correct the data, once you have fixed the consumer.
Kafka has been designed as a high throughput messaging system, with capabilities of high scalability. It is highly reliable and durable. The api’s have been developed keeping loose coupling between the producer and consumer in mind. It provides a flexible semantics to consume and publish messages.
Kafka Architecture
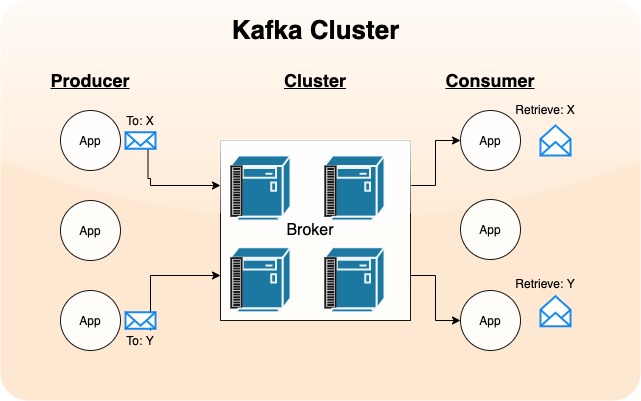
Kafka bases itself on the publisher/subscriber model. In kafka world, publisher is called as Producer and subscriber is referred as Consumer. To simply put producer publishes message to central location called as Topic, the consumer receives the message and process them.

The Broker manages all the topics, and the broker can reside on a single/multiple host. Multiple brokers’ comes together to form a cluster, which is managed by Apache Zookeeper.
There are lots of concepts, but for now let proceed with getting the hands dirty.
Installing Kafka
The first step is to download the Kafka on your machine, I am using a mac(steps will be similar for other OS as well).
Extract the zip to your local machine
$ tar -xvf kafka_2.12-2.5.0.tgz
$ cd kafka_2.12-2.5.0
Configure Zookeeper
Before we start, we need to configure the zookeeper. We need to modify zookeeper.properties.
$ vi config/zookeeper.properties
By default, the zookeeper stores the data at /tmp/zookeeper, I will modify it to use a custom directory zookeeper-data. To do that, we need to change the dataDir in the zookeeper.properties file.
$ mkdir zookeeper-data
My modified zookeeper.properties file look like this:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the directory where the snapshot is stored.
dataDir=/zookeeper-data
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=false
# admin.serverPort=8080
Starting zookeeper
To run the zookeeper we need to goto bin folder and run the following command.
$ cd bin
$ ./zookeeper-server-start.sh ../config/zookeeper.properties
This should start the zookeeper, now let’s move to kafka.
Configure Kafka
Similarly, we are going to modify kafka configuration. To do that we need to modify log.dirs in config/server.properties to point to custom directory. By default, it points to /tmp/kafka-logs.
Now lets start the server:
$ cd bin
$ ./kafka-server-start.sh ../config/server.properties
Kafka should be up and running.
Create Kafka Topic
As per the documentation: A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it For now we are using commandline utility provided by kafka to create a topic. We will create a topic with single replication factor since we are running a single broker instance.
$ ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic test.
$
The above command creates a topic named test. we will use this topic to publish our messages.
Publish Messages
We will again use the commandline utility to publish the message to Kafka topic../
$ ./kafka-console-producer.sh --broker-list localhost:9092 --topic test
>message 1
>message 2
>message 3
Receiving Messages
We will use the kafka console consumer to connect to Kafka at port 9092 and receive message from test topic.
$ ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
message 1
message 2
message 3
We have successfully started single broker of Kafka with the zookeeper, published and consumed the messages.
If you liked this article, you can buy me a coffee
Leave a comment